요약
– 요약: “단일” 에지 서버에서 애플리케이션 실행 효율을 향상시키기 위한 연구
– 소개 : 에지 서버의 경우 리소스가 제한되어 있고 물리적 환경이 다르기 때문에 경량 컨테이너 가상화가 좋은 선택이지만 데몬 프로세스에 의한 컨테이너 관리 및 컨테이너 간 통신은 상당한 CPU 리소스를 소비합니다.
– 관련 연구 : Edge Server와 Cloud를 활용한 Workload Planning 및 베어메탈 기반 Machine에서의 시나리오 연구를 통한 작업 수행 효율성 향상에 대한 연구 -> 단일 Edge Server에서 컨테이너의 효율성 향상에 대한 연구는 수행되지 않음
– 방법: 일반적인 작업 스케줄링 및 컨테이너화 기법 제안
– 실험: 광범위한 시뮬레이션을 통해 평가한 비효율적인 컨테이너 작업 감소 및 애플리케이션 실행 효율성 60% 향상
– 결론 및 논의: JTSC 방식이 다양한 요구사항을 만족함과 동시에 비효율적인 컨테이너 운영을 줄이고 애플리케이션 실행 효율을 향상시키는 것으로 나타났지만, 더 복잡한 시나리오에서 테스트할 여지가 있다.
소개
에지 서버는 리소스가 제한되어 있고 물리적 환경이 다릅니다. 또한 지능형 교통, 비디오 분석, 증강 현실, 스마트 홈을 비롯한 광범위한 애플리케이션을 지원하므로 가상화는 소프트웨어 종속성 충돌을 피하는 좋은 방법이 될 수 있습니다.



컨테이너는 단일 운영 체제 커널을 공유하면서 독립적인 파일 시스템 및 환경으로 프로세스를 격리하고 실행하는 일종의 가상화 기술입니다. 엣지 환경에서 이러한 컨테이너 기술을 배포할 때
- 경량 실행 환경: 컨테이너는 가상화 기술 중 가장 가벼운 기술이기 때문에 에지 장치와 같이 리소스가 제한된 환경에서도 효율적으로 실행할 수 있습니다.
- 격리된 실행 환경: 컨테이너는 독립적인 파일 시스템과 환경을 가지고 있기 때문에 다양한 애플리케이션이 격리된 환경에서 실행될 수 있습니다. 이렇게 하면 응용 프로그램 간의 상호 작용을 방지하고 보안을 강화할 수 있습니다.
- 확장성: 컨테이너는 쉽게 생성, 복제, 이동, 삭제 등을 할 수 있으므로 에지 환경에서 애플리케이션을 쉽게 확장 또는 축소할 수 있습니다.
경량 컨테이너 가상화로 소프트웨어 종속성을 피할 수 있지만 컨테이너 간 통신과 컨테이너 관리로 인해 데몬 프로세스에서 상당량의 CPU 리소스를 소모하는 문제가 있습니다.

예비 실험을 통해 확인한 결과, (a) 컨테이너 간 통신이 컨테이너 내 통신과 유사할 때 CPU 활용도가 낮다. (b) 컨테이너에서 더 많은 작업이 시작되면 데몬 프로세스가 더 많은 리소스를 소비합니다.
컨테이너 효율성을 향상시키는 방법은 두 가지가 있으며 본 논문에서는 기존 컨테이너 시스템의 변경이 필요 없는 후자의 방법을 사용한다.
1. 커스텀 컨테이너가 컨테이너 작업에 소비하는 CPU 리소스를 줄이는 방법
2. 비효율적인 컨테이너 작업의 사용을 줄이는 방법
비효율적인 컨테이너 작업은 애플리케이션 작업 스케줄링 및 작업-컨테이너 매핑 방식에 의존하므로 비효율적인 컨테이너 작업을 줄이기 위해서는 스케줄링과 컨테이너화를 함께 고려해야 합니다.
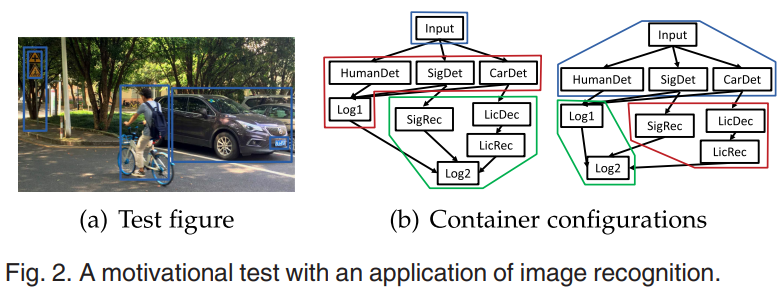
예를 들어, 이미지 인식 애플리케이션(a)은 (b)와 같이 서로 다른 작업으로 구성됩니다. 각각의 작업을 컨테이너로 나누면 오른쪽 방법은 왼쪽 방법에 비해 컨테이너 간 통신을 74%, 데몬 프로세스가 소모하는 CPU 자원을 29% 줄일 수 있다. 또한 올바른 방법은 왼쪽 방법보다 작업 시간이 더 짧습니다.
따라서 본 문서에서는 컨테이너 작업을 최적화하기 위해 애플리케이션의 구성(태스크 간의 관계)을 보여주는 애플리케이션 모델을 생성하고 각 태스크와 컨테이너의 CPU 자원 활용률과 실행 시간을 보여주는 실행 모델을 생성한다. 그리고 이 모델을 기반으로 공통 태스크 스케줄링 및 컨테이너화 시스템(JTSC)을 설계합니다.
이 논문의 기여는 다음과 같습니다.
- 단일 에지 서버에서 컨테이너 작업에 사용되는 CPU 리소스를 정량화하고 작업 실행에 미치는 영향을 분석합니다.
- 컨테이너화 프레임워크 및 알고리즘은 컨테이너화 체계 및 작업 스케줄링을 지정하여 컨테이너 워크로드 및 애플리케이션 실행 시간을 낮게 유지하도록 설계되었습니다.
배경
2.1.1. 컨테이너
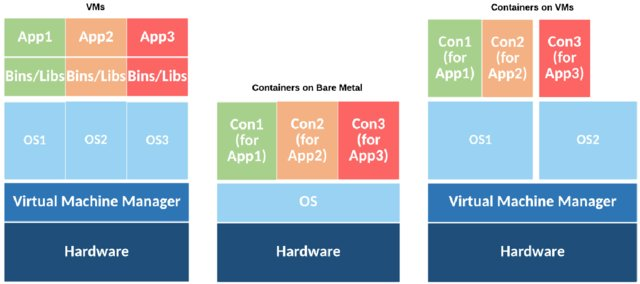
컨테이너 및 가상 머신은 단일 리소스를 “가상화”하고 여러 리소스로 나타낼 수 있는 프로세스입니다.
가상 머신은 전체 머신을 하드웨어 수준까지 가상화하는 반면 컨테이너는 운영 체제 수준 위의 소프트웨어 수준만 가상화합니다.
따라서 컨테이너는 운영 체제 커널을 호스트와 공유하기 때문에 가상 머신보다 가볍습니다. 격리된 환경은 두 가지 운영 체제 메커니즘인 네임스페이스와 cgroup에 의해 제공됩니다.
- 네임스페이스: 서로 다른 컨테이너에 대해 서로 격리된 리소스를 유지합니다. B. 호스트 이름 및 도메인 이름, 파일 마운트 지점, IPC(프로세스 간 통신)에 대한 정보, PID(프로세스 식별자), 네트워크 스택 및 사용자.
- cgroup: 다른 컨테이너의 프로세스가 사용하는 시스템 리소스를 제한하고 프로세스 중지/재개를 제어합니다.
2.1.2. 악마
데몬은 백그라운드 프로세스로 계속 실행되는 프로그램으로, 원격 프로세스의 주기적인 서비스 요청을 처리하기 위해 자주 깨어납니다. 데몬 프로세스는 컨테이너 관리 프레임워크에서 실행됩니다. B. 컨테이너 시작 및 중지, 이미지 관리 등
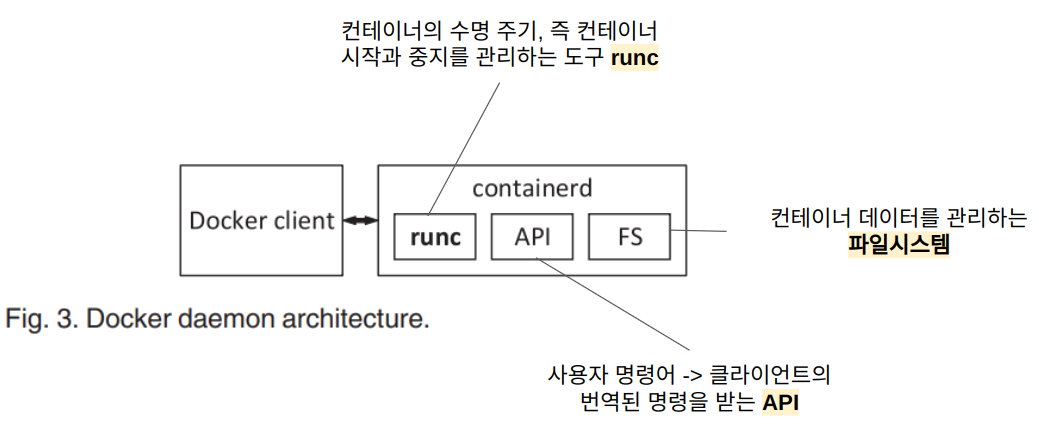
컨테이너호스트에서 컨테이너의 수명 주기를 관리하고 컨테이너를 생성, 시작, 종료 및 파괴하는 컨테이너 런타임입니다. 또한 컨테이너 레지스트리에서 컨테이너 이미지를 가져오고, 스토리지를 프로비저닝하고, 컨테이너에 대한 네트워킹을 활성화할 수 있습니다. Containerd는 다음과 같이 구성되어 있으며 각 구성 요소는 서로 협력하여 컨테이너 작업을 수행합니다.
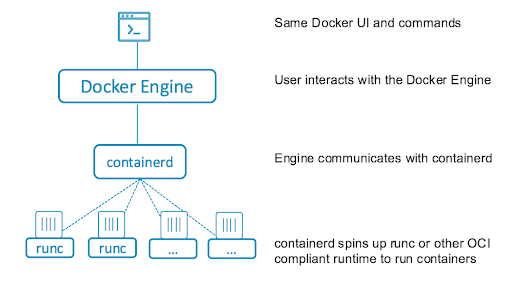
containerd는 백그라운드 프로세스로 실행되는 데몬으로 대화형 사용자가 직접 제어하지 않으며 위와 동일한 동작을 합니다.
2.1.3. 회로망
서로 다른 컨테이너의 네임스페이스가 격리되어 있기 때문에 공유 메모리를 통한 IPC는 서로 다른 컨테이너의 프로세스 간에 데이터를 전송하는 데 직접 사용할 수 없습니다. Docker는 가상 스위치, 브리지를 사용하여 서로 다른 네트워크 세그먼트를 연결하여 컨테이너 간에 데이터를 전송합니다.
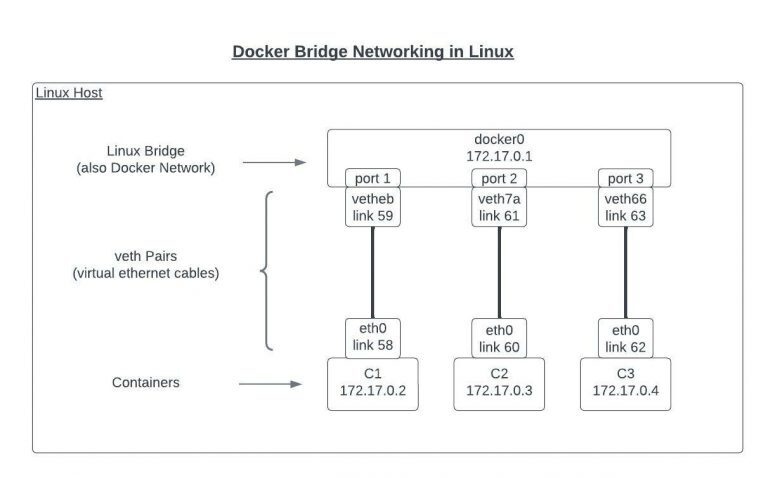
데몬 프로세스가 초기화되면 브리지 인스턴스가 시작되고 Veth(가상 이더넷)가 네임스페이스 간의 터널 역할을 합니다. Veth는 일반적으로 컨테이너에 하나, 브리지에 다른 하나 등 쌍으로 생성됩니다. 결과적으로 브리지에 연결된 veth 장치가 있는 모든 컨테이너는 동일한 서브넷에 있으며 서로 간에 데이터를 전송할 수 있습니다. 이러한 브릿지를 통한 데이터 전송은 데이터의 패킹과 언패킹 등의 절차가 필요하기 때문에 IPC에 비해 비효율적이라는 단점이 있다.
예비 테스트
컨테이너 작동에 대한 실험
실험은 최신 컨테이너 관리 프레임워크인 Docker와 널리 사용되는 컴퓨팅 플랫폼 X86 및 ARM을 사용하여 수행되었습니다.
3.1. 컨테이너 간 통신
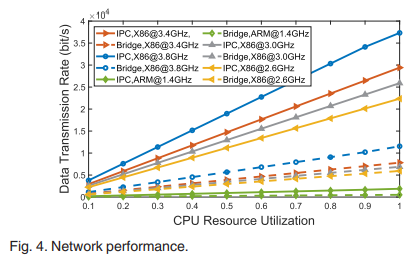
Netperf 클라이언트와 서버를 두 개의 컨테이너(브리지를 통한 통신) 또는 동일한 컨테이너(IPC와의 통신)에 배포하여 두 호스트 간의 네트워크 대역폭을 측정합니다. 클라이언트는 가변적인 CPU 사용량(10-100%)을 가지며 180초 동안 서버에 데이터 패킷을 계속 전송합니다. 위의 그래프에서 볼 수 있듯이 브리지 네트워크 또는 IPC의 전송 속도는 할당된 CPU 리소스에 따라 선형적으로 증가하며, 이는 전송 속도가 CPU 리소스 소비량과 밀접한 관련이 있음을 나타냅니다.
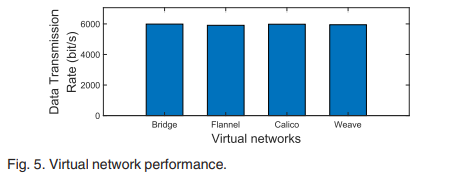
그리고 그림 5에 따르면 네트워크 가상화 방식에 상관없이 데이터 전송률은 거의 동일하다.
3.2. 데몬 프로세스에 의한 컨테이너 관리
컨테이너 작업이 실행되면 데몬 프로세스의 CPU 리소스 사용량을 기록하고 실험을 실행합니다.
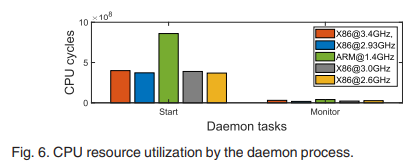
그림 6에서 볼 수 있듯이 데몬 프로세스가 20개의 컨테이너를 시작하는 데 사용하는 CPU 리소스는 컨테이너를 모니터링하는 데 사용되는 리소스를 훨씬 초과합니다. 그 이유는 다음과 같습니다.
- 컨테이너 시작: 여기에는 리소스 제한 설정, 네트워크 구성, 볼륨 탑재 등이 포함됩니다.
- 모니터링: 컨테이너 상태를 주기적으로 확인하기만 하면 됩니다.
위의 예비 실험은 컨테이너 간 통신이 컨테이너 내 통신보다 덜 효율적이라는 것을 보여주었습니다. 그러나 서로 다른 컨테이너에 연결된 태스크 간의 데이터 전송은 컨테이너 간 통신이 불가피하기 때문에 데이터 전송 속도가 느려 컨테이너가 없을 때보다 이러한 태스크가 실행될 때 실행 시간이 길어진다. 따라서 컨테이너 간 통신량을 줄여 애플리케이션 실행 시간에 미치는 영향을 줄이기 위해 컨테이너화 방법을 신중하게 선택해야 합니다.
컨테이너를 시작할 때 데몬 프로세스는 작업 실행을 위해 리소스를 사전 할당하는 상당한 CPU 리소스를 사용하며 애플리케이션의 총 컨테이너 시작 시간은 총 컨테이너 수와 각 컨테이너의 시작 횟수라는 두 가지 요소에 따라 달라집니다. 컨테이너 수는 컨테이너화 체계에 의해 결정되며 컨테이너 시작 빈도는 컨테이너의 작업 일정에 따라 다릅니다. 따라서 컨테이너화된 애플리케이션을 최적화하기 위해서는 작업 스케줄링과 컨테이너화를 모두 고려하는 것이 중요하다는 것을 알 수 있었습니다.
행동 양식
실험에 사용된 응용 프로그램은 실제 응용 프로그램을 표현하기에는 너무 단순하기 때문에 이 기사에서는 실험 결과를 일반 응용 프로그램으로 확장하기 위해 응용 프로그램 모델과 실행 모델의 두 가지 시스템 모델을 생성합니다.
- 애플리케이션 모델: 일반적인 에지 컴퓨팅 애플리케이션의 구성을 설명합니다.
- 일반적으로 애플리케이션은 표준 API로 연결된 여러 모듈로 구성되며 이러한 모듈이 입력 데이터를 처리한 다음 출력 데이터를 생성하는 프로세스를 작업이라고 합니다. 작업 간에 종속성이 있으며 고려해야 할 세 가지 유형의 작업 종속성(소프트웨어 종속성, 데이터 종속성 및 결합)이 있습니다.
- 소프트웨어 종속성: 소프트웨어 구성 요소에 의존
- 데이터 종속성: 작업은 다른 작업의 출력에 따라 달라집니다.
- 결합: 전역 변수와 같은 공유 처리 구성 요소에 대해 두 작업이 서로 종속됩니다.
- 위의 종속성 때문에 서로 다른 컨테이너에 낮은 결합 작업을 배포하여 작업 오류의 영향 범위를 줄이고 동일한 컨테이너에서 높은 종속성 작업을 실행하는 것이 좋습니다.
- 일반적으로 애플리케이션은 표준 API로 연결된 여러 모듈로 구성되며 이러한 모듈이 입력 데이터를 처리한 다음 출력 데이터를 생성하는 프로세스를 작업이라고 합니다. 작업 간에 종속성이 있으며 고려해야 할 세 가지 유형의 작업 종속성(소프트웨어 종속성, 데이터 종속성 및 결합)이 있습니다.
- 실행 모델: 애플리케이션(작업 및 컨테이너 작업 포함)의 CPU 리소스 사용량과 에지 서버에서 작업 실행 시간을 보여줍니다.
- 실행 중인 작업의 수명 주기는 세 단계로 나눌 수 있습니다. 작업이 차단되면 입력 데이터가 메모리에 캐시되고 CPU 리소스가 사용되지 않습니다. 작업이 모든 데이터 입력을 받은 후 다음 실행을 위해 작업이 예약됩니다. 작업이 완료되면 출력 데이터는 즉시 하위 작업으로 전송되어 데이터 전송 기간 동안 CPU 리소스를 소비합니다.
- 차단됨: 일부 입력 데이터를 사용할 수 없거나 예약되지 않은 경우
- 작업
- 전송: 출력 데이터 전송
- 실행 중인 작업의 수명 주기는 세 단계로 나눌 수 있습니다. 작업이 차단되면 입력 데이터가 메모리에 캐시되고 CPU 리소스가 사용되지 않습니다. 작업이 모든 데이터 입력을 받은 후 다음 실행을 위해 작업이 예약됩니다. 작업이 완료되면 출력 데이터는 즉시 하위 작업으로 전송되어 데이터 전송 기간 동안 CPU 리소스를 소비합니다.
즉, 비효율적인 작업(상호 의존적 작업)을 줄이고 애플리케이션 실행 시간을 짧게 유지하는 규칙을 설정합니다.
- 컨테이너 간의 통신이 비효율적이기 때문에 데이터 전송량이 많은 작업을 동일한 컨테이너에 할당합니다.
- 적절한 작업 예약을 통해 컨테이너 수를 줄여 컨테이너 시작 횟수를 줄입니다.
- 컨테이너 간 통신을 위해 두 작업 간의 CPU 유휴 시간을 활용합니다.
- 유휴 시간: 이 원칙에 따르면 프로세서의 유휴 시간은 병렬 컴퓨팅에서 1) 모든 상위 작업과 2) 동일한 프로세서에서 예약된 이전 작업이 완료될 때까지 작업을 시작할 수 없기 때문에 존재합니다. 이 유휴 시간 동안 컨테이너 간의 통신이 제대로 수행될 수 있으면 동일한 프로세서에서 후속 작업이 지연되지 않을 수 있습니다.
- 실행 시간에 상당한 영향을 미치는 작업 중에는 컨테이너 간 통신을 피하십시오.
그리고 위의 규칙을 따르는 공통 계획 및 컨테이너화 시스템을 제안합니다.
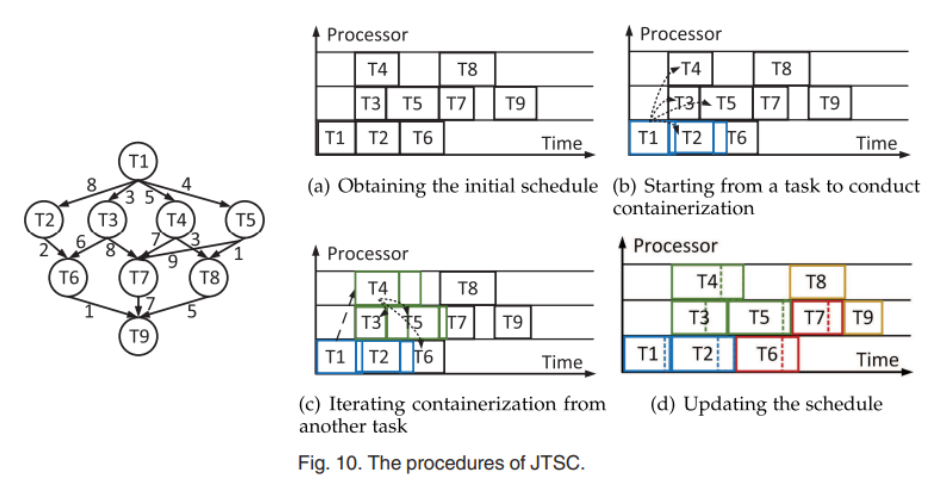
- 먼저 할당된 프로세서에서 작업을 예약하여 “초기 계획”을 얻습니다.
- 컨테이너 작업은 이 작업에서 고려되지 않습니다.
- 비효율적인 작업을 줄이기 위해 초기 일정에 따라 작업을 컨테이너에 할당합니다.
- 이 작업에서는 컨테이너화 방식(작업-컨테이너 매핑)이 결정됩니다.
- 컨테이너 간 통신으로 인해 작업 수행 시간이 변경될 수 있으므로 초기 일정을 적용할 수 없습니다. 따라서 작업 일정은 컨테이너화 스키마에서 얻은 새 작업 실행 기간을 기반으로 업데이트됩니다.
평가
이 문서에서는 실제 워크플로를 사용하여 작업과 종속 항목으로 구성된 JTSC를 평가했습니다. 각 태스크는 데이터 처리를 위한 컨테이너 간의 통신 비율에 대한 CPU 리소스 계산량의 비율(0.1, 0.5, 1, 5, 10)을 가집니다. 작업 간의 종속성은 종속성 충돌을 표시하기 위해 일부 요소가 무한대로 설정된 매트릭스로 표시되었습니다.
JTSC의 성과는 특정 지표를 기반으로 평가됩니다. B. 컨테이너 간 전송 횟수, 컨테이너 시작 횟수, 특정 애플리케이션의 실행 시간 및 JTSC 실행 시간.
- CPF: 임계 경로 우선 알고리즘
- STO: 타임스탬프 주문 시작
- ICRO: Idle Time to Communication Ratio Order 알고리즘
- Rand: 실행 가능한 컨테이너화 체계를 무작위로 찾습니다.
- SFD: 가장 작은 ICP
- SFC: 가장 작은 CST
- SFE: 가장 작은 NED
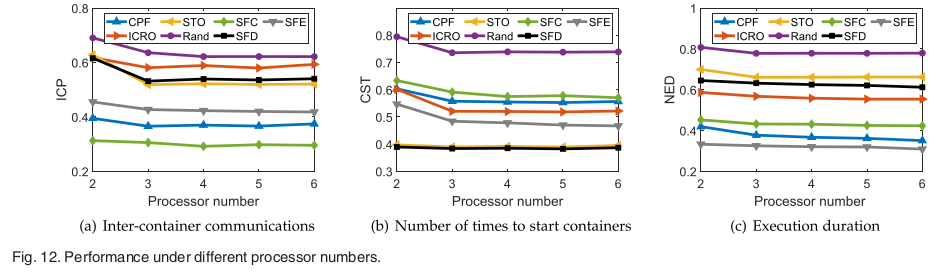
이 기사에 따르면 모든 컨테이너화 알고리즘은 컨테이너 간의 통신과 컨테이너 시작 횟수를 줄이는 측면에서 장단점이 있음이 밝혀졌습니다. 그리고 이 문서에서 제시하는 JTSC는 복잡도가 낮고 다양한 응용 프로그램에서 잘 작동합니다.
- 통신 집약적인 작업의 경우 CPF 및 ICRO가 더 잘 수행됩니다.
- STO는 컨테이너를 자주 시작하고 중지해야 하는 작업에 더 나은 성능을 제공합니다.